 NeoBit Daily
NeoBit Daily

Build Custom 2026 Software Update Policies: Step-by-Step
Advanced IT administrators face increasing pressure to move beyond default vendor update schedules. Custom policies allow organizations to align patching with specific risk profiles, compliance mandates, and operational goals. This guide provides a practical framework for constructing 2026 software update policies that incorporate patch analysis, security intelligence, and phased deployment strategies. By tailoring these elements, teams can reduce exposure windows while maintaining system stability across complex enterprise landscapes.
Assessing Organizational Requirements
Before drafting any policy, map business-critical systems, regulatory obligations, and acceptable downtime windows. Conduct stakeholder interviews across security, operations, and application teams to identify constraints. For example, a financial services firm might prioritize zero-downtime requirements for trading platforms while accepting faster patching on internal HR tools. Document asset inventories using tools such as configuration management databases and categorize systems by data sensitivity, user impact, and recovery time objectives. This foundation ensures subsequent policy decisions remain grounded in real operational needs rather than generic vendor timelines. Include considerations for hybrid cloud environments where update behaviors differ between on-premises servers and containerized workloads. Regular reassessment every quarter helps adapt to mergers, new applications, or shifting compliance landscapes.
Analyzing Patch Notes and Release Notes
Effective policies begin with disciplined review of vendor documentation. Establish a weekly cadence for examining release notes from major platforms including Microsoft, Adobe, and Linux distributions. Focus on severity ratings, exploitability details, affected components, and any mentioned workarounds. Create internal scoring rubrics that weigh factors such as remote code execution potential, public exploit availability, and dependency chains. In enterprise environments, teams often discover that a moderate-severity update for a widely used library carries higher organizational risk than a critical update affecting only niche hardware. Maintain a living spreadsheet or database to track historical patterns, noting which vendors consistently provide clear remediation steps versus those requiring additional reverse engineering. Cross-reference with internal incident logs to refine scoring accuracy over time.
National Institute of Standards and Technology guidance on vulnerability management provides useful context for standardizing these evaluations across teams.
Integrating Security Signals from Updates
Modern policies incorporate threat intelligence feeds alongside traditional patch data. Subscribe to sources such as CISA alerts and vendor security blogs to correlate update content with active campaigns. This step transforms reactive patching into proactive risk reduction. Build automated workflows that flag updates matching known indicators of compromise. One healthcare provider implemented a script that cross-references Microsoft security bulletins with MITRE ATT&CK mappings, enabling same-day decisions on high-impact vulnerabilities. Integrate signals from endpoint detection platforms to prioritize updates that address tactics observed in recent attacks against peer organizations. Document every correlation decision to support future audits and continuous improvement of the scoring model.
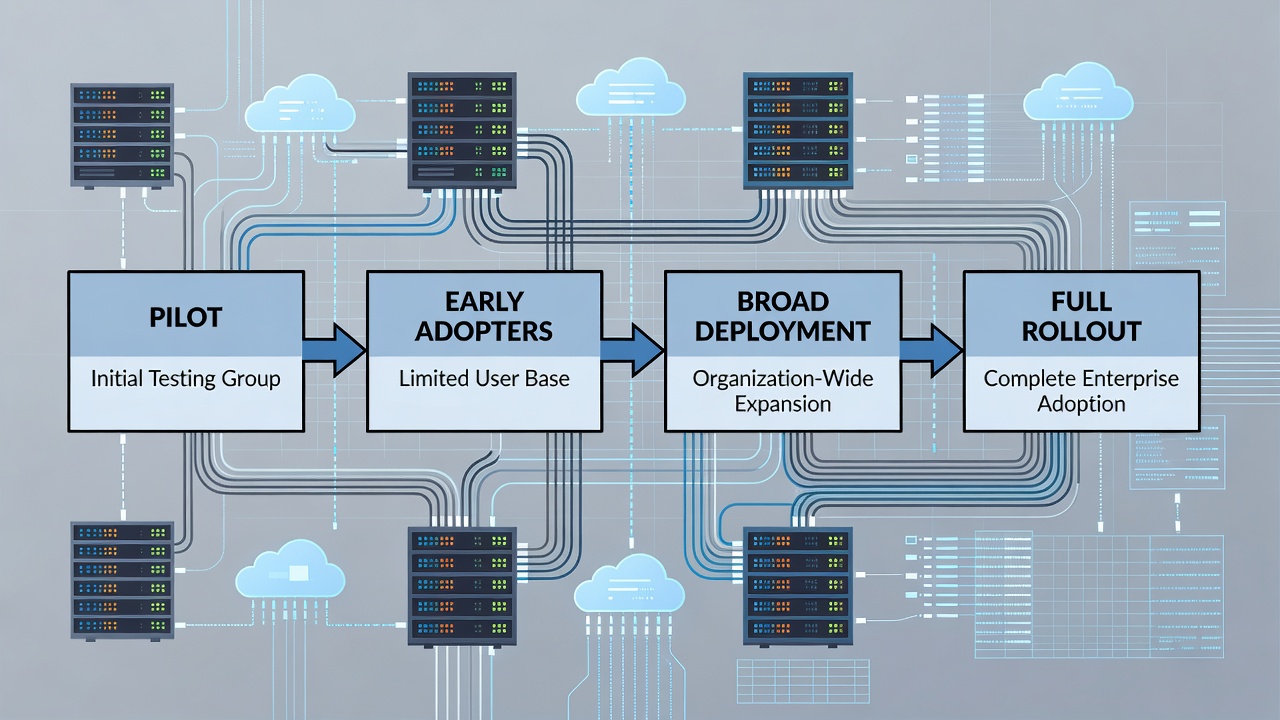
Building Tiered Rollout Schedules
Tiered deployments reduce blast radius while accelerating protection for critical assets. A typical four-tier model includes pilot, early adopters, broad deployment, and full rollout groups. Define success criteria at each stage, such as error rates below 0.5 percent and no critical application regressions. Adjust timing based on update complexity; browser updates may move through tiers in 48 hours while enterprise resource planning patches often require two-week validation windows. Incorporate automated canary testing in the pilot phase using synthetic transactions to detect performance degradation early. Establish clear rollback procedures with predefined triggers, such as user-reported issues exceeding a set threshold or monitoring alerts indicating widespread instability. Communication templates for each tier help minimize support ticket volume during transitions.
- Pilot group: 5 percent of endpoints representing diverse hardware and user roles
- Early adopters: 15 percent of systems including key application servers
- Broad deployment: 60 percent of the environment after pilot validation
- Full rollout: Remaining systems with extended monitoring
Comparing Policy Frameworks
Organizations commonly evaluate three approaches: time-based, risk-based, and hybrid models. Time-based policies follow fixed calendars and suit stable environments with predictable workloads. Risk-based frameworks dynamically adjust cadence using threat data and prove valuable for high-exposure sectors such as finance and healthcare. Hybrid models combine scheduled baseline updates with expedited handling of critical vulnerabilities. Real-world comparisons show hybrid approaches reduce mean time to remediation significantly compared with purely calendar-driven methods. Evaluate frameworks against your asset diversity and regulatory environment before committing to one model, and consider piloting elements of each to measure internal fit.
Practical Enterprise Examples
A multinational retailer implemented a custom policy that delayed non-security feature updates by 30 days on point-of-sale systems while accelerating security patches within 72 hours. This balance maintained compliance with PCI DSS requirements without disrupting seasonal sales peaks. Another case involved a government contractor that layered conditional access rules requiring successful update verification before granting VPN connectivity. A manufacturing company extended this further by creating environment-specific exceptions for industrial control systems, routing those updates through a separate air-gapped validation lab before production deployment. These examples illustrate how granular segmentation supports both security posture and operational continuity.
Establishing Metrics for Success and Iteration
Track key performance indicators including patch compliance percentage, average time from release to deployment, and post-update incident rates. Schedule quarterly policy reviews that incorporate feedback from helpdesk tickets and security assessments. Use these metrics to refine tier definitions and scoring rubrics, ensuring the policy evolves alongside the threat landscape and organizational changes.
Downloadable Checklist and Common Pitfalls
Use the following checklist when designing your policy: inventory all update sources and maintain a centralized repository; define risk scoring criteria with input from multiple teams; establish tier definitions with rollback procedures and communication plans; schedule regular policy reviews with documented outcomes; and document exceptions with expiration dates and responsible owners. Avoid common mistakes such as over-reliance on default settings that ignore custom applications, neglecting legacy system exceptions that create persistent vulnerabilities, and failing to test update interactions with internally developed software. Another frequent pitfall is insufficient stakeholder buy-in, which leads to shadow IT workarounds that bypass the intended controls.
FAQs on Compliance and Customization
How do custom policies address regulatory compliance?
They allow explicit mapping of update timelines to specific controls such as those in NIST SP 800-40 or ISO 27001, with documented justifications for deviations that auditors can review easily.
What are frequent customization pitfalls?
Teams often underestimate testing scope for interdependent applications and overlook communication plans, leading to user confusion during phased rollouts and increased support burden.
How should organizations handle updates for legacy systems?
Apply compensating controls such as network segmentation and enhanced monitoring while planning migration roadmaps, and include these systems in the exception process with clear timelines for retirement.
By following the structured approach outlined above, IT leaders can create durable, organization-specific update policies that balance security, stability, and business continuity throughout 2026 and beyond.

No comments yet. Be the first!