 NeoBit Daily
NeoBit Daily
Introduction
In 2026, machine learning practitioners face an overwhelming volume of new research, tools, and breakthroughs emerging daily from academic labs, open-source communities, and industry leaders. Integrating real-time AI news into ML pipelines allows teams to stay ahead by rapidly incorporating relevant advancements that can improve accuracy, efficiency, and capabilities. This comprehensive guide provides actionable strategies for setting up automated monitoring systems, intelligently filtering updates for relevance, and translating emerging insights into tangible pipeline improvements that deliver measurable results.
Whether you are working on natural language processing models, computer vision systems, or reinforcement learning agents, the ability to ingest and act on fresh information separates leading organizations from those that lag. Throughout this article we explore concrete implementation patterns, real deployment examples, platform comparisons, and proven safeguards against common failure modes.
Why Real-Time AI News Matters for ML Pipelines
Staying current with AI developments can directly enhance model accuracy, reduce training times, and unlock entirely new architectures. For instance, a new optimization technique announced on arXiv could improve convergence rates in production models by double-digit percentages when adapted correctly. Without real-time integration, teams risk falling behind competitors who leverage these insights faster and achieve superior business outcomes. Recent shifts in attention mechanisms and efficient transformer variants have already demonstrated how timely adoption can cut inference costs while maintaining quality. Organizations that systematically monitor and experiment with new methods report faster iteration cycles and higher innovation velocity across their entire ML portfolio.
Setting Up Automated News Feeds with AI Tools
Begin by selecting reliable sources such as academic repositories and tech platforms. Use tools like RSS readers enhanced with AI summarization or custom scripts leveraging APIs from arXiv and Hugging Face. Configure webhooks to push notifications into your workflow management system, such as integrating with Slack, Microsoft Teams, or a dedicated internal dashboard that surfaces high-priority items to data scientists and engineers.
Automate ingestion using Python scripts with libraries like feedparser combined with NLP models for initial categorization and entity extraction. This setup ensures continuous updates without manual intervention. You can further enrich the pipeline by connecting to Papers with Code endpoints that link new papers directly to reproducible implementations. Schedule polling intervals as frequently as every fifteen minutes during peak research release periods, while applying rate limiting to respect API quotas. Logging every ingested item with metadata such as publication date, source credibility score, and initial relevance probability creates an auditable trail for later analysis.
Filtering Relevant Machine Learning Updates
Not every news item applies to your domain. Implement filters based on keywords, model types, performance metrics, and hardware constraints. Use topic modeling or embedding similarity to score relevance automatically. For example, prioritize updates mentioning transformers, mixture-of-experts architectures, or reinforcement learning if those align with your current stack. Advanced filtering can include sentiment analysis on community discussions from GitHub issues and Twitter threads to gauge adoption potential and maturity level of new methods. Maintain a living taxonomy of your technical priorities that evolves quarterly, ensuring the filter remains aligned with roadmap goals. Incorporate human-in-the-loop review for borderline cases where automated scores fall in the middle range, allowing domain experts to refine the classifier over time.
Translating Insights into Actionable Pipeline Changes
Once filtered, map news items to concrete actions. A new dataset release might trigger data augmentation steps or synthetic data generation modules, while an efficiency paper could inspire hyperparameter adjustments or quantization strategies. Document changes in version-controlled pipeline configs using tools like DVC or MLflow to maintain reproducibility and enable rollback if experiments underperform. Establish clear ownership so that each high-scoring insight is assigned to a specific engineer or team for prototyping within a defined timeframe, typically 48 to 72 hours for initial feasibility checks.
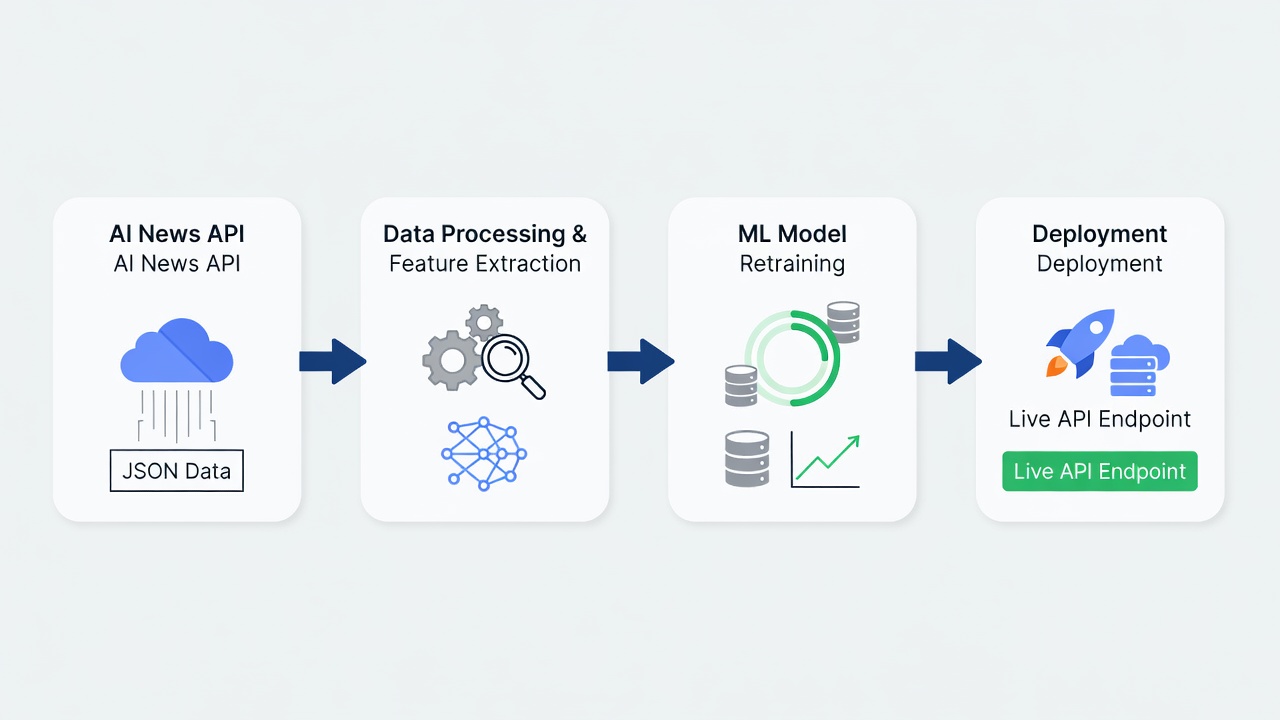
Step-by-Step Integration Examples
Consider this end-to-end workflow used successfully by multiple production teams: 1) Monitor feeds hourly using a lightweight cron job. 2) Score articles using a fine-tuned classifier trained on your historical accepted papers. 3) Generate pull requests automatically with suggested code updates, including links back to source material. 4) Run A/B tests on staging environments before full deployment, tracking metrics such as latency, accuracy, and resource utilization. 5) Archive outcomes and feed them back into the relevance model for continuous improvement. Real-world teams at leading labs have used similar approaches to adopt techniques like mixture-of-experts models within weeks of publication, achieving substantial gains in both performance and cost efficiency.
Comparisons of Popular Aggregation Platforms
Several platforms stand out when building a robust news ingestion layer. Feedly excels at customizable AI topic boards and seamless team collaboration features, making it ideal for cross-functional groups. Google Alerts combined with custom scripts offers a free baseline but requires more engineering effort to achieve sophisticated filtering and deduplication. Specialized tools such as Perplexity AI integrations provide conversational querying of recent papers, enabling rapid synthesis of key findings without reading every abstract. When evaluating options, consider factors including API access limits, export capabilities, integration with version control, and support for custom relevance scoring. A hybrid approach that combines two platforms often delivers the best coverage while mitigating single-point failures.
Common Pitfalls to Avoid
Over-filtering can miss serendipitous discoveries that later prove transformative. Ensure scalability by stress-testing your pipeline under high-volume news periods, such as major conference weeks. Always validate new techniques on your specific datasets rather than assuming universal improvements, because domain shift frequently negates claimed gains. Additional pitfalls include failing to version-control prompt changes when using LLMs for summarization, neglecting to monitor source credibility drift, and under-investing in notification fatigue prevention. Build automated alerts that surface only items above a dynamic relevance threshold to keep engineers engaged rather than overwhelmed.
Quick-Start Checklist
- Identify 5-10 core keywords tied to your models and business objectives.
- Set up at least two automated feeds from authoritative sources with proper authentication.
- Build a relevance scoring module using embeddings and maintain a feedback loop for model updates.
- Schedule weekly review meetings to discuss top insights and assign ownership.
- Track impact metrics such as model performance deltas, adoption rate of new techniques, and time from discovery to production deployment.
- Establish rollback procedures and maintain a living document of experiments and outcomes.
Real-World Case Snippets
A fintech team integrated news on new fraud detection algorithms announced in late 2025, leading to a 15 percent reduction in false positives within their production pipeline after targeted retraining. An autonomous vehicle startup adopted emerging sensor fusion methods reported in recent papers, accelerating their development cycle by several months and improving obstacle detection in adverse weather. In healthcare, a diagnostics company incorporated a novel self-supervised learning approach within six weeks of its preprint release, resulting in measurable gains on rare disease classification tasks. These examples illustrate how structured news integration translates directly into competitive advantage when executed with discipline and rigorous experimentation.
FAQ
How accurate are automated AI news summaries?
Accuracy depends on the underlying NLP models and the quality of source material. Always cross-reference critical claims with original papers and run controlled experiments before committing changes to production pipelines.
Can this scale for large teams with hundreds of models?
Yes. Distributed processing, intelligent caching, and hierarchical filtering allow systems to handle thousands of daily updates efficiently while surfacing only the most relevant items to individual teams.
What if news contains conflicting information or unverified claims?
Prioritize peer-reviewed publications and preprints from reputable institutions. Maintain an internal validation framework that requires statistical significance on your own benchmarks before any technique is promoted beyond the experimentation stage.
How do you measure the ROI of news integration efforts?
Track metrics such as time-to-adoption for new methods, percentage of experiments that reach production, and downstream improvements in accuracy or cost. Over a six-month period these indicators typically reveal clear value when the program is well executed.
Conclusion
Integrating real-time AI news transforms reactive ML development into a proactive, innovation-driven process. By following the outlined steps, building robust filtering mechanisms, and maintaining disciplined experimentation practices, practitioners can consistently improve their pipelines and maintain a competitive edge throughout 2026 and beyond. The organizations that treat news integration as a core capability rather than an afterthought will be best positioned to capitalize on the rapid pace of advancement in artificial intelligence.

No comments yet. Be the first!