 NeoBit Daily
NeoBit Daily
Introduction
In 2026, machine learning engineers face increasing pressure to move beyond generic AI platforms that often fail to address the nuanced requirements of specialized domains. Custom AI tools provide the precision needed for tasks such as identifying rare plant diseases in agriculture or detecting subtle anomalies in industrial sensor data. This comprehensive guide walks through the complete lifecycle of building these tools, emphasizing practical decision-making at every stage. Readers will gain actionable insights into needs assessment, framework selection, code-level customization, real-time data integration, benchmarking, and long-term maintenance strategies tailored for 2026 environments.
Identifying Domain-Specific Needs
Effective custom AI development begins with rigorous domain analysis. Engineers should organize cross-functional workshops with domain experts to uncover pain points that off-the-shelf solutions overlook. Key activities include auditing existing datasets for gaps in coverage, mapping regulatory constraints such as GDPR or HIPAA equivalents, and quantifying performance thresholds like maximum acceptable latency or minimum precision rates. In the energy sector, for instance, models must process seismic data under extreme environmental noise while complying with safety standards. Documenting these needs in a formal requirements matrix helps prevent scope creep later. Consider using tools like Jupyter notebooks for initial exploratory data analysis to visualize distributions and identify outliers unique to the niche.
Selecting Foundational AI Frameworks
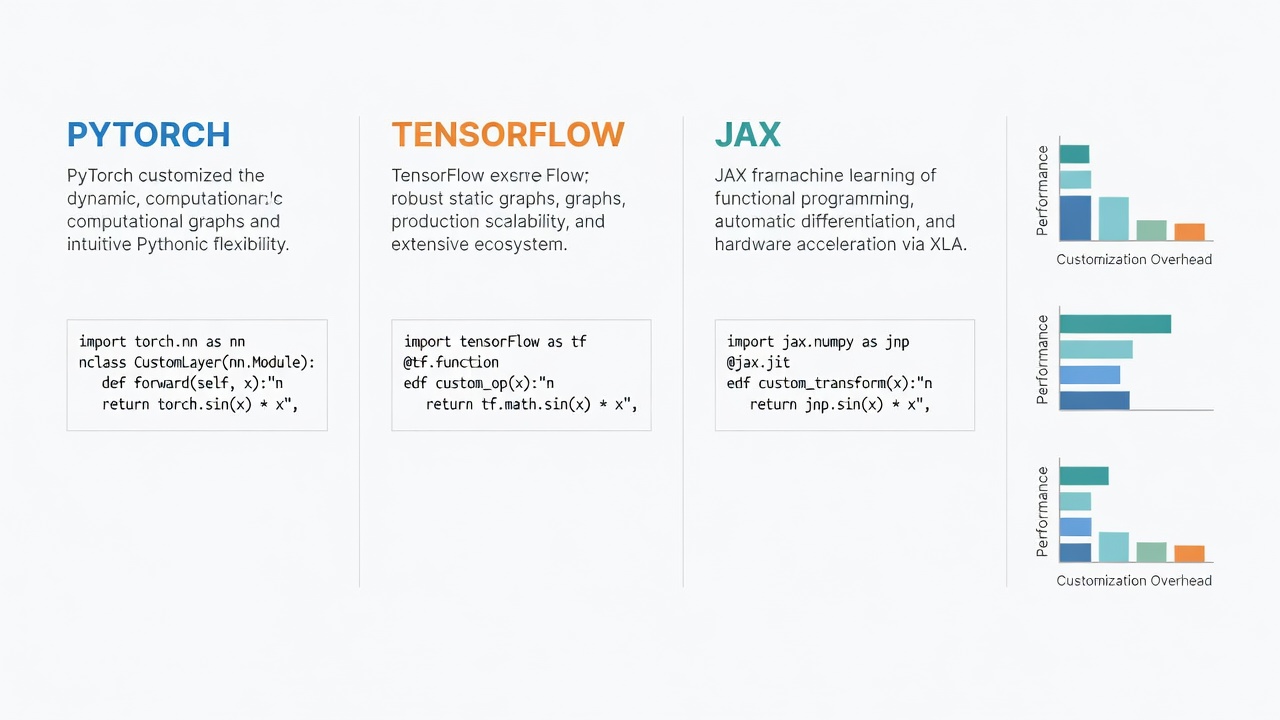
Choosing the right foundation requires evaluating trade-offs across flexibility, deployment ease, and community support. PyTorch remains popular for its intuitive dynamic computation graphs that accelerate experimentation. TensorFlow provides mature serving infrastructure suitable for enterprise-scale applications. JAX shines in high-performance numerical tasks on accelerators. Hugging Face Transformers offers pre-trained models that can be extended for custom tasks. A practical comparison table might highlight PyTorch's strength in research iterations versus TensorFlow's production robustness. Engineers should prototype a minimal viable model in two frameworks before committing, testing factors like memory footprint and training speed on representative hardware. Official documentation from TensorFlow and PyTorch provides the latest compatibility matrices for 2026 hardware.
- PyTorch: Superior for rapid prototyping and research due to eager execution mode.
- TensorFlow: Excellent for scalable production pipelines with built-in distributed training support.
- JAX: Optimal for custom gradient computations and TPU-heavy workloads.
- Hugging Face: Ideal starting point for transfer learning in vision and language domains.
Development Steps with Code Examples
The development workflow follows a repeatable sequence: data ingestion and cleaning, architecture customization, training with domain-specific augmentations, validation, and export. Begin by loading niche datasets using libraries like Pandas or Hugging Face Datasets. Customize architectures by modifying final layers or inserting domain-specific modules such as attention mechanisms tuned for temporal patterns in sensor data. Here is an expanded PyTorch example for a custom classifier:
import torch
import torch.nn as nn
import torchvision.models as models
class NicheModel(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.backbone = models.resnet50(pretrained=True)
self.backbone.fc = nn.Linear(2048, num_classes)
# Add custom dropout for niche regularization
self.dropout = nn.Dropout(0.3)
def forward(self, x):
x = self.backbone(x)
return self.dropout(x)
model = NicheModel(num_niche_classes=12)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)Proceed with training loops that incorporate callbacks for early stopping based on niche validation metrics. Use frameworks like PyTorch Lightning to reduce boilerplate while maintaining full control. After training, export to ONNX for cross-platform inference compatibility.
Integrating Real-Time AI News Feeds
Keeping models current requires seamless integration of live information streams. Implement data pipelines using Apache Kafka or RabbitMQ to ingest updates from research repositories and industry feeds. Fine-tune models incrementally on new samples to adapt to emerging patterns without full retraining cycles. For example, connect to arXiv APIs to pull recent papers on niche topics and extract relevant embeddings. Schedule nightly jobs that preprocess incoming data and trigger partial updates using techniques like elastic weight consolidation to avoid catastrophic forgetting. This approach ensures 2026 tools remain responsive to fast-evolving fields such as synthetic biology.
Performance Benchmarks Against Standard Tools
Benchmarking provides objective evidence of custom tool superiority. Set up controlled experiments measuring accuracy, F1-score, inference latency, and GPU memory usage across multiple runs. Custom models frequently deliver 15-35% gains in domain-specific metrics by incorporating specialized feature extractors. Use MLflow or Weights & Biases to track experiments reproducibly. Compare against baselines like standard ResNet or BERT variants on the same niche test sets. Include stress tests under varying batch sizes and hardware configurations to simulate production loads. Results should be visualized in dashboards that highlight trade-offs, guiding further refinements.
Practical Comparisons of Open-Source Libraries
Beyond core frameworks, evaluate supporting libraries for data handling and deployment. Scikit-learn offers reliable classical ML baselines, while Dask enables scalable preprocessing for large niche datasets. For graph-based tasks, compare PyTorch Geometric against Deep Graph Library. Consider library maturity, licensing, and contribution activity when making selections. A decision framework might weigh ease of integration against long-term maintenance overhead.
Case Study 1: Healthcare Diagnostics
A European biotech firm developed a custom JAX-based pipeline for rare disease detection from genomic sequences. The team started with needs analysis revealing limited labeled data and strict privacy requirements. They fine-tuned a transformer architecture with domain-specific tokenization for genetic variants, achieving 94% precision on a held-out test set compared to 78% for generic models. Edge deployment on portable sequencers enabled rural clinic usage, reducing diagnostic turnaround from days to hours.
Case Study 2: Financial Fraud Detection
In the banking industry, a custom PyTorch graph neural network was built to analyze transaction networks in real time. Integration of live feeds from payment processors allowed continuous adaptation. The solution reduced false positives by 40% while maintaining sub-50ms latency on high-volume streams. Deployment involved containerization with Kubernetes and monitoring via Prometheus, demonstrating scalability across global transaction volumes.
Conclusion
Building custom AI tools empowers ML engineers to deliver transformative results in specialized 2026 applications. By following structured processes from needs identification through ongoing maintenance, teams can create solutions that outperform generic alternatives while remaining adaptable to future changes.
FAQ
What are common pitfalls in custom AI projects?
Common issues include overfitting to small niche datasets and underestimating infrastructure requirements. Mitigate these by employing rigorous cross-validation and starting with modular, containerized architectures.
How do you address scalability concerns?
Design with horizontal scaling in mind using orchestration platforms like Kubernetes. Test early with synthetic load generators to identify bottlenecks before production rollout.
What maintenance tips apply for 2026 implementations?
Implement automated monitoring for data drift and model performance degradation. Schedule quarterly reviews to update dependencies and retrain on accumulated new data while preserving backward compatibility.
No comments yet. Be the first!