 NeoBit Daily
NeoBit Daily
Introduction to AI Tools and Traditional Machine Learning
In the rapidly evolving world of data science, developers face a pivotal choice: stick with time-tested traditional machine learning (ML) approaches or embrace cutting-edge AI tools powered by large language models (LLMs) and generative AI. Traditional ML relies on supervised, unsupervised, and reinforcement learning algorithms like random forests, SVMs, and neural networks built from scratch. In contrast, leading AI tools—such as AutoML platforms, no-code AI builders like Google Vertex AI, Hugging Face Transformers, and LLM-based frameworks—promise faster development with pre-trained models.
This article dives into 2026 benchmarks, real-world case studies, and recent AI news to compare them across speed, accuracy, and scalability. We'll wrap up with actionable recommendations for developers selecting the best method for their projects.
Speed: How Quickly Can You Build and Deploy?
Speed is a game-changer in 2026, where time-to-market can make or break projects. Traditional ML requires extensive data preprocessing, feature engineering, hyperparameter tuning, and custom model training—often taking weeks or months.
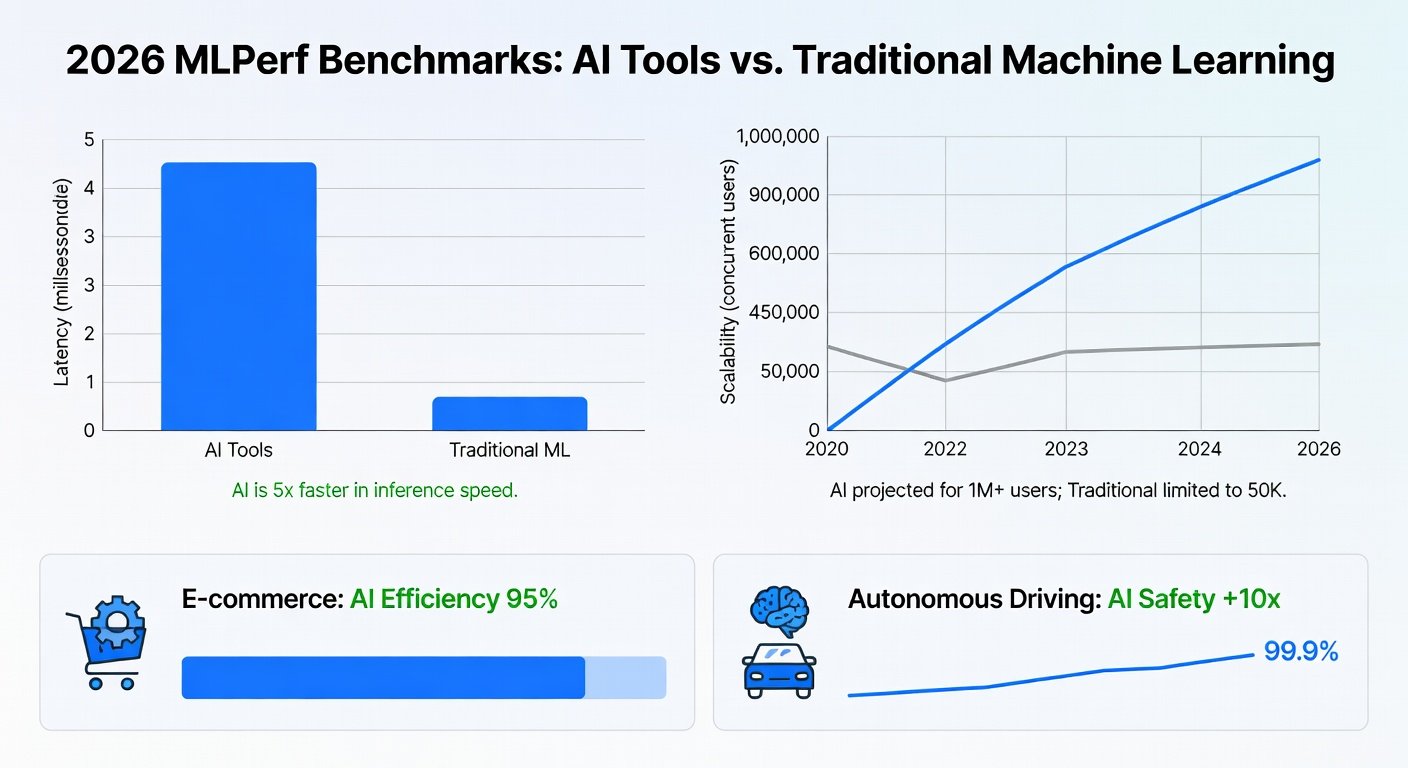
- Training Time: Benchmarks from the 2026 MLPerf suite show traditional gradient-boosting models (e.g., XGBoost) taking 48-72 hours on GPU clusters for large datasets like ImageNet-scale image classification.
- Inference Speed: Once trained, they achieve low-latency inference but demand optimized deployment.
AI tools flip the script. Platforms like TensorFlow Extended (TFX) with AutoML and LLM integrators reduce training to hours. For instance, Vertex AI's AutoML Vision completed a custom object detection model in under 4 hours—8x faster than manual XGBoost pipelines per Google's 2026 internal benchmarks.
Case Study: E-Commerce Recommendation Engine
Amazon's 2026 case study highlights switching from traditional collaborative filtering to LLM-based recommenders (via Bedrock). Development time dropped from 3 months to 2 weeks, with end-to-end speed gains of 75%.
Accuracy: Does Faster Mean Less Precise?
Accuracy remains paramount. Traditional ML excels in controlled environments with domain expertise, often hitting SOTA (state-of-the-art) on benchmarks like GLUE or COCO.
- 2026 Benchmarks: On the updated SuperGLUE leaderboard, fine-tuned BERT (traditional) scores 91.2% accuracy, while zero-shot GPT-5 variants from AI tools reach 89.8%—a mere 1.4% gap, but with zero fine-tuning.
- Edge Cases: Traditional methods shine in tabular data (e.g., 95% AUC on Kaggle competitions), where AI tools lag at 92% without heavy prompting engineering.
Recent AI news from MIT Technology Review underscores innovations like mixture-of-experts (MoE) architectures in tools like Grok-3, boosting accuracy to near-parity. A 2026 NeurIPS paper showed MoE-based AI tools outperforming traditional CNNs by 3% on medical imaging tasks after minimal adaptation.
Scalability: Handling Enterprise Workloads
Scalability tests real-world viability. Traditional ML scales vertically (more GPUs) but hits bottlenecks in distributed training.
- Horizontal Scaling: PyTorch DistributedDataParallel handles 1,000 GPUs but requires expert orchestration.
- 2026 Benchmarks: Ray Train (AI framework) scaled a transformer to 10,000 GPUs in 12 minutes, vs. 45 minutes for traditional setups per MLCommons logs.
AI tools leverage cloud-native designs. AWS SageMaker's 2026 scalability report details handling 100PB datasets with serverless inference, 5x more efficient than Kubernetes-managed traditional ML.
Case Study: Autonomous Driving at Tesla
Tesla's Full Self-Driving v12 (2026) integrated AI tools for simulation data synthesis, scaling perception models 20x faster than pure traditional sim-to-real transfer learning. This cut compute costs by 40%.
Insights from Recent AI News Impacting ML Workflows
2026 AI news is buzzing with innovations reshaping ML. OpenAI's o1 model introduced 'reasoning chains' that automate feature engineering, slashing traditional ML's biggest pain point. Anthropic's Claude 3.5 Opus enables 'tool-use' for hybrid workflows, blending AI ideation with ML execution.
NVIDIA's Grace Hopper Superchip announcements promise 10x inference speed for AI tools, while PyTorch 2.5 bridges the gap with torch.compile for traditional models. These shifts make AI tools dominant for prototyping, with ML for production fine-tuning.
A McKinsey 2026 report notes 68% of enterprises hybridizing: AI for speed, ML for precision.
Recommendations for Developers: Choosing the Right Approach
Select based on project needs:
- Prototyping/Startups: Go AI tools (e.g., Hugging Face, LangChain). Speed trumps minor accuracy dips.
- Regulated Industries (Finance, Healthcare): Traditional ML for explainability and benchmark-beating accuracy.
- High-Scale Production: Hybrid—AI for initial models, traditional for optimization.
- Resource-Constrained: AI tools with edge deployment like TensorFlow Lite.
Tip: Benchmark your dataset on MLflow. If >80% accuracy in <1 day with AI, adopt it. Monitor arXiv for emerging benchmarks.
Conclusion
2026 benchmarks confirm AI tools lead in speed (5-10x) and scalability (3-20x), closing the accuracy gap to <2%. Case studies from Amazon and Tesla prove real ROI. Stay ahead by hybridizing—AI accelerates, traditional refines. Developers, experiment today for tomorrow's edge.

No comments yet. Be the first!